Nœud de base
La plateforme propose plusieurs types de nœuds permettant de construire des workflows flexibles et puissants. On distingue principalement les nœuds de base, qui servent à orchestrer la logique générale du système, comme les déclencheurs, les conditions ou les actions. Ces nœuds constituent le socle de toute automatisation et permettent de gérer le flux principal des données et des événements. Ils sont essentiels pour définir la structure du workflow et assurer son bon fonctionnement dans différents scénarios d’exécution.
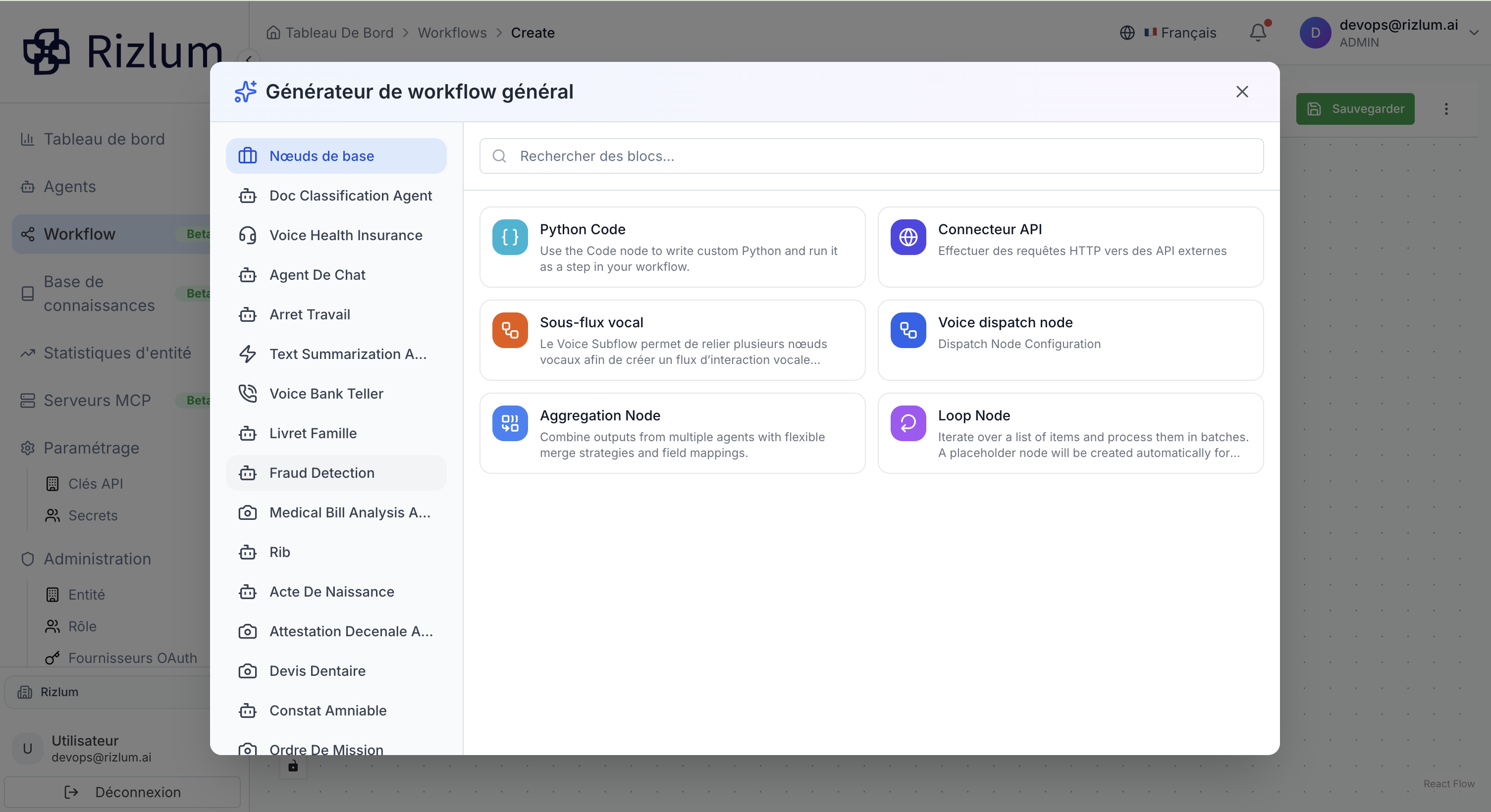
Dans la plateforme, ces six types de nœuds constituent des composants fonctionnels fondamentaux du workflow. Chaque nœud remplit un rôle opérationnel précis : exécution de code (Python), intégration avec des services externes (Connecteur API), gestion des interactions vocales (Sous-flux vocal et Voice Dispatch), agrégation de données (Aggregation Node) et contrôle de flux (Loop Node). Contrairement aux nœuds dits agents, qui encapsulent des capacités intelligentes ou spécifiques à un fournisseur, ces nœuds de base sont agnostiques et structurent la logique globale du processus. Ils servent de briques modulaires pour orchestrer, transformer et acheminer les données au sein du workflow.
1. Python code
Le nœud Python a pour objectif de réaliser des opérations d’analyse et de transformation sur les données issues des nœuds précédents dans un workflow. Il permet de manipuler ces sorties afin de produire de nouveaux résultats, plus adaptés aux besoins du traitement en cours. Grâce à la flexibilité du langage Python, ce nœud peut exécuter des calculs complexes, appliquer des règles métiers, filtrer ou enrichir les données, ou encore restructurer les informations pour les rendre exploitables par les étapes suivantes.
Les valeurs générées par ce nœud constituent ensuite les sorties qui seront utilisées par les nœuds en aval du workflow. Cela permet de créer des enchaînements logiques où chaque étape dépend des transformations effectuées précédemment. Le nœud Python joue ainsi un rôle central dans l’orchestration et la personnalisation des flux de données, en offrant un contrôle précis sur la manière dont les informations sont traitées et transmises. Il s’intègre facilement dans des scénarios variés, allant de simples ajustements de données à des traitements analytiques avancés.
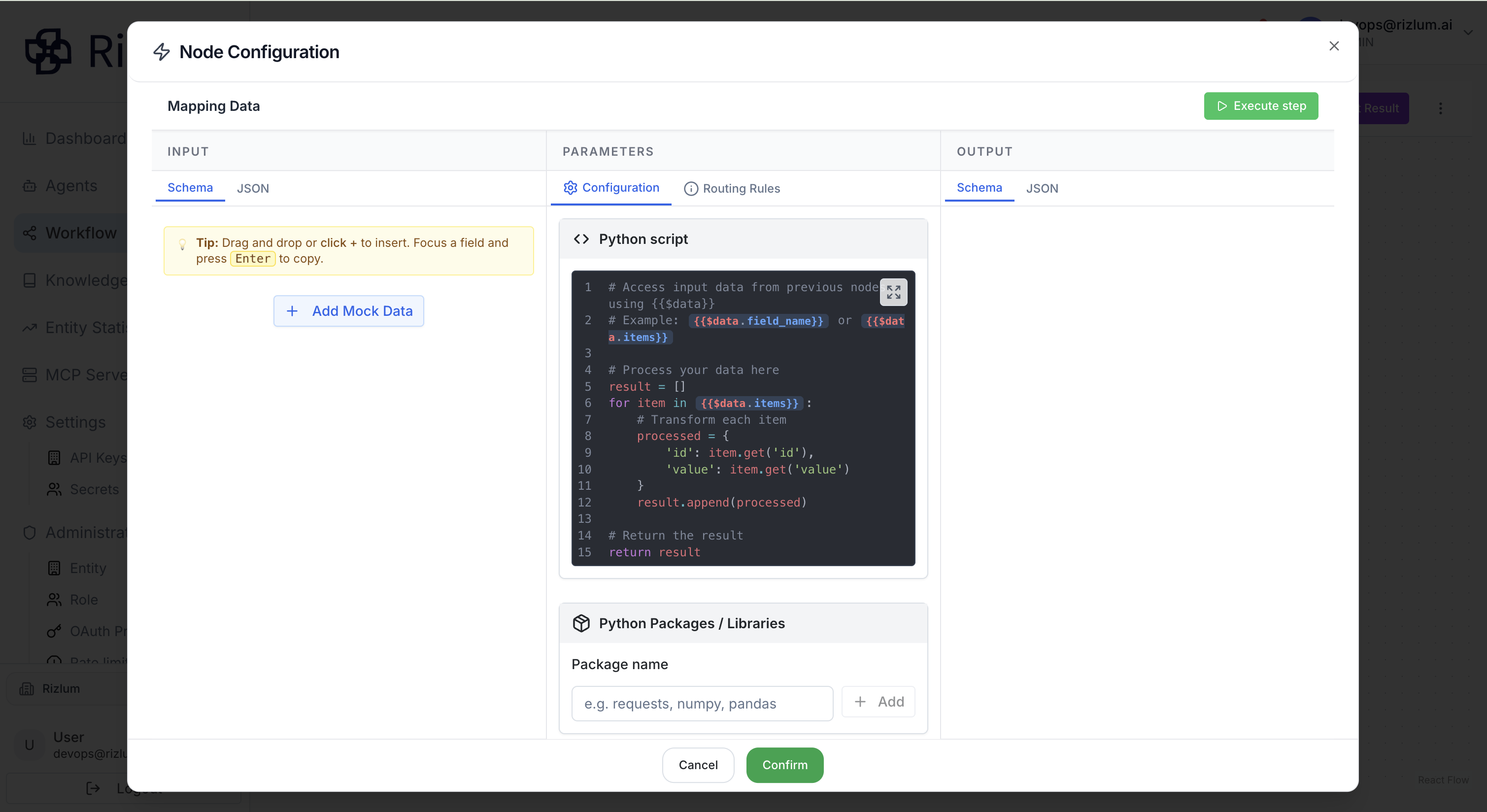
Le champ de nom de ce nœud est obligatoire.
La section de configuration comprend un espace dédié au code Python, dans lequel un script par défaut est fourni afin d’aider les utilisateurs à comprendre rapidement le fonctionnement du nœud. Cet exemple initial sert de point de départ et peut être modifié selon les besoins. Les utilisateurs peuvent y glisser-déposer (drag & drop) les données d’entrée provenant des nœuds précédents, puis écrire leur propre logique de traitement directement en Python. Cette approche permet de transformer les données en appliquant des règles spécifiques, des conditions ou des calculs, afin de produire des résultats conformes aux objectifs du workflow.
Attention : dans la logique de code Python définie dans ce nœud, il est indispensable de toujours retourner au moins une valeur. En effet, l’instruction de retour (return) permet de produire les données de sortie du nœud, qui seront ensuite transmises et exploitées par les étapes suivantes du workflow. Sans cette valeur de sortie, le nœud ne pourra pas générer de résultat utilisable, ce qui risque d’interrompre ou de perturber l’exécution globale du flux.
Il est donc recommandé de structurer le code de manière à garantir qu’un résultat cohérent est systématiquement renvoyé, qu’il s’agisse d’un objet, d’une liste ou de toute autre structure de données attendue.
En complément, cette section propose également un champ permettant d’ajouter des bibliothèques Python nécessaires à l’exécution du code. Les utilisateurs peuvent ainsi intégrer facilement des packages courants tels que numpy, pandas ou requests, selon les exigences de leur traitement. Cette flexibilité permet d’étendre les capacités du nœud en facilitant l’analyse avancée, la manipulation de données ou l’intégration avec des services externes. Grâce à cette configuration, le nœud Python devient un outil puissant et adaptable pour construire des logiques de transformation sur mesure.
2. Connecteur API
Le nœud Connecteur API permet d’interagir avec des services externes en appelant des API situées en dehors du périmètre de la plateforme agent et du workflow lui-même. Il joue un rôle essentiel pour enrichir les traitements en intégrant des données ou des fonctionnalités provenant de systèmes tiers, tels que des services web, des bases de données distantes ou des applications SaaS. Grâce à ce nœud, il devient possible d’étendre considérablement les capacités du workflow en le connectant à des sources externes, tout en conservant une logique d’orchestration centralisée.
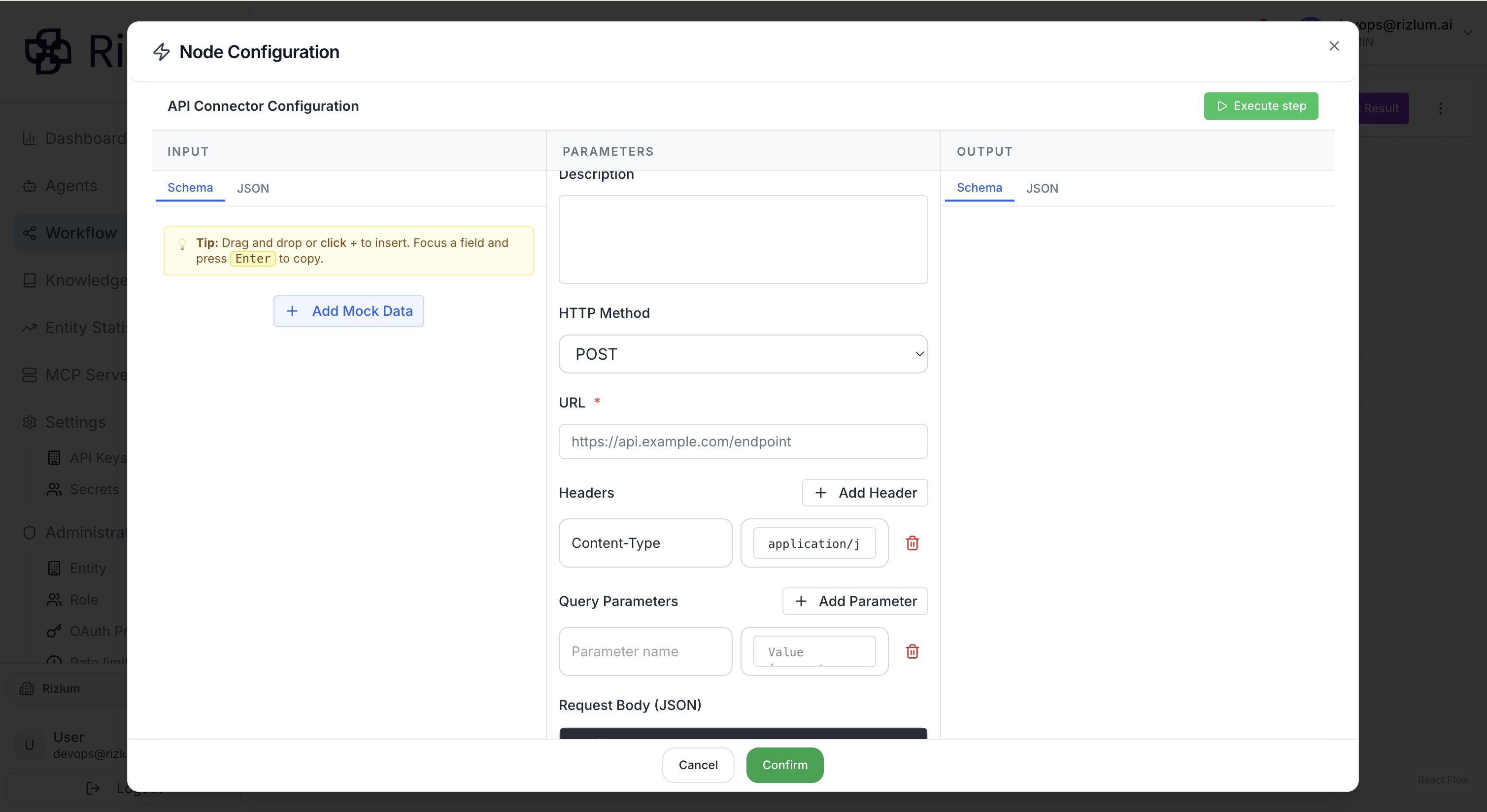
Le champ de nom de ce nœud est obligatoire.
Pour accompagner l’utilisateur dans cette fonctionnalité, la section de configuration propose un ensemble de paramètres nécessaires à l’appel d’une API standard:
- Le premier élément requis est la méthode HTTP, qui est obligatoire. L’utilisateur doit choisir parmi les méthodes classiques telles que GET, POST, PUT, DELETE ou PATCH, selon l’action souhaitée sur l’API cible.
- Le champ URL correspond à l’adresse de l’API à appeler. Il s’agit du point d’entrée du service externe. L’utilisateur doit y renseigner l’endpoint complet, incluant éventuellement des paramètres dynamiques.
- La section Header (en-têtes) offre la possibilité d’ajouter plusieurs en-têtes HTTP nécessaires à la requête. Cela inclut par exemple les informations d’authentification (comme les tokens Bearer), les types de contenu (Content-Type), ou tout autre paramètre requis par l’API. L’utilisateur peut définir autant de paires clé-valeur que nécessaire, et y intégrer des données dynamiques provenant des étapes précédentes du workflow.
- La configuration des paramètres de requête (query parameters) permet d’ajouter plusieurs paramètres directement dans l’URL. Ces paramètres sont souvent utilisés pour filtrer, trier ou paginer les résultats retournés par l’API.
- Le champ corps de la requête (request body) est utilisé principalement avec les méthodes telles que POST, PUT ou PATCH. Il permet de transmettre des données structurées à l’API, généralement sous forme de JSON. L’utilisateur peut y définir le contenu de la requête en fonction des besoins du service appelé, en combinant valeurs statiques et données issues des nœuds précédents.
Enfin, pour l’ensemble des champs mentionnés ci-dessus, la plateforme offre une fonctionnalité de glisser-déposer (drag & drop) permettant d’insérer facilement les données d’entrée provenant des nœuds précédents. Cette capacité facilite la création de requêtes dynamiques et contextuelles, en reliant directement les sorties des étapes antérieures aux paramètres de l’appel API. Cela permet de construire des intégrations puissantes et flexibles, adaptées à des cas d’usage variés.
3. Sous-flux vocal
L’objectif de ce nœud est de structurer un appel vocal sans le transférer vers d’autres flux, tout en maintenant le traitement actif tout au long de la conversation. Il agit comme un orchestrateur central dans lequel l’utilisateur peut organiser plusieurs comportements du voice bot de manière séquentielle. À l’intérieur de ce nœud, il est possible d’ajouter et de connecter différents sous-nœuds afin de définir précisément l’ordre d’exécution des actions. Par exemple, un premier agent peut accueillir l’utilisateur, un second poser des questions de qualification, et un troisième traiter une demande spécifique. Le flux reste actif en continu : aucune logique n’est interrompue tant que l’appel n’est pas explicitement terminé.
Ce nœud permet ainsi d’enchaîner plusieurs logiques, analyses et interactions dans un seul appel, sans rupture dans l’expérience utilisateur. Chaque agent vocal peut être spécialisé dans une tâche précise, comme la collecte d’informations, la validation ou la réponse contextuelle, et intervenir au moment défini dans le flux. L’appel ne se termine pas dans ce nœud : la fin de la conversation est gérée par un nœud dédié de type « finish » du sous-flux. Cette séparation garantit une meilleure maîtrise du cycle de vie de l’appel, tout en permettant de concevoir des scénarios conversationnels complexes, dynamiques et parfaitement fluides.
Pour ajouter et configurer un nœud Sous-flux vocal, suivez les étapes ci-dessous :
1.Pour ajouter un nœud Sous-flux vocal, cliquez sur Ajouter un nœud, puis sélectionnez la section Nœuds de base et choisissez Sous-flux vocal. Une fois sélectionné, le nœud apparaît dans l’espace de workflow.
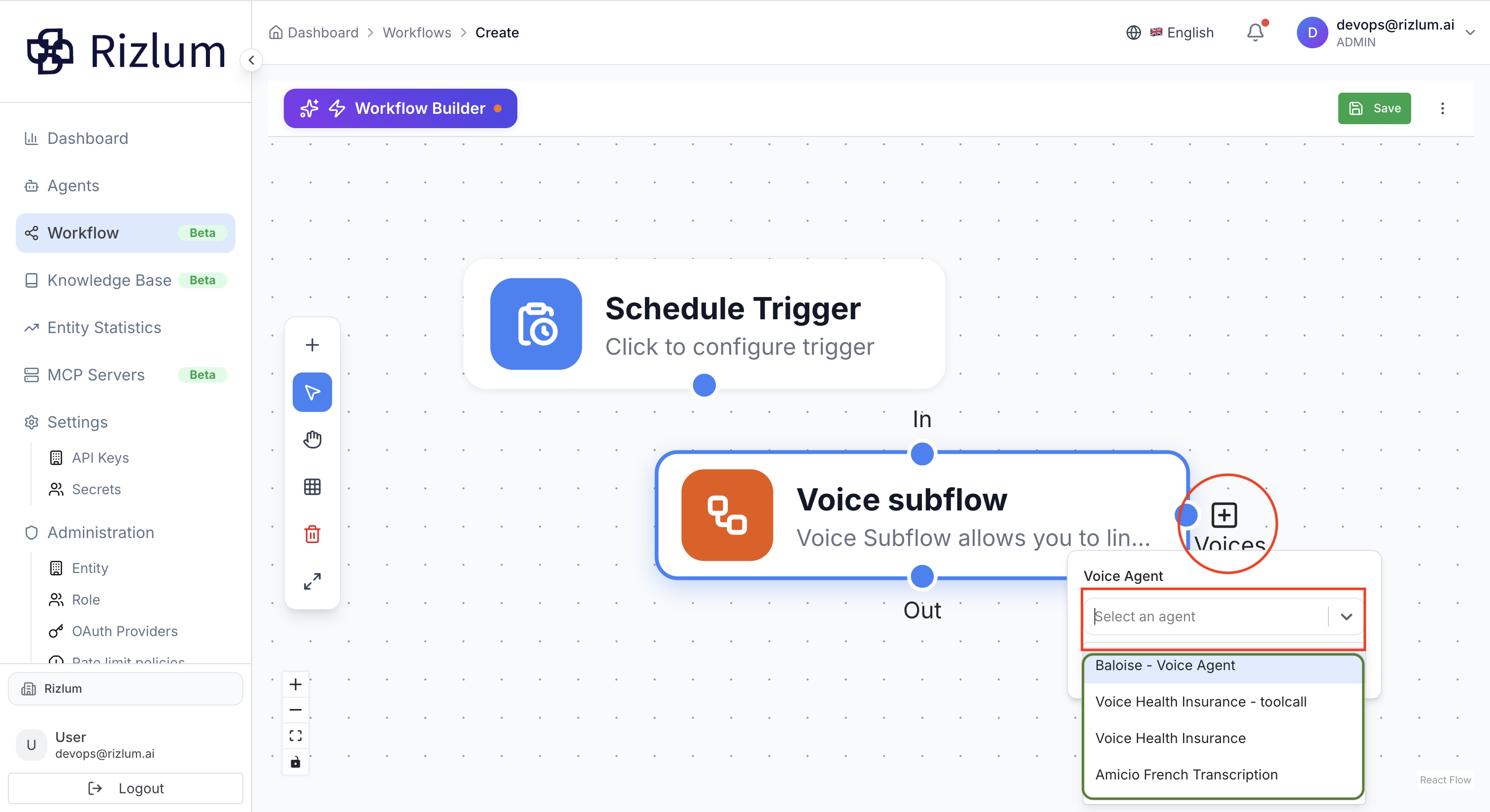
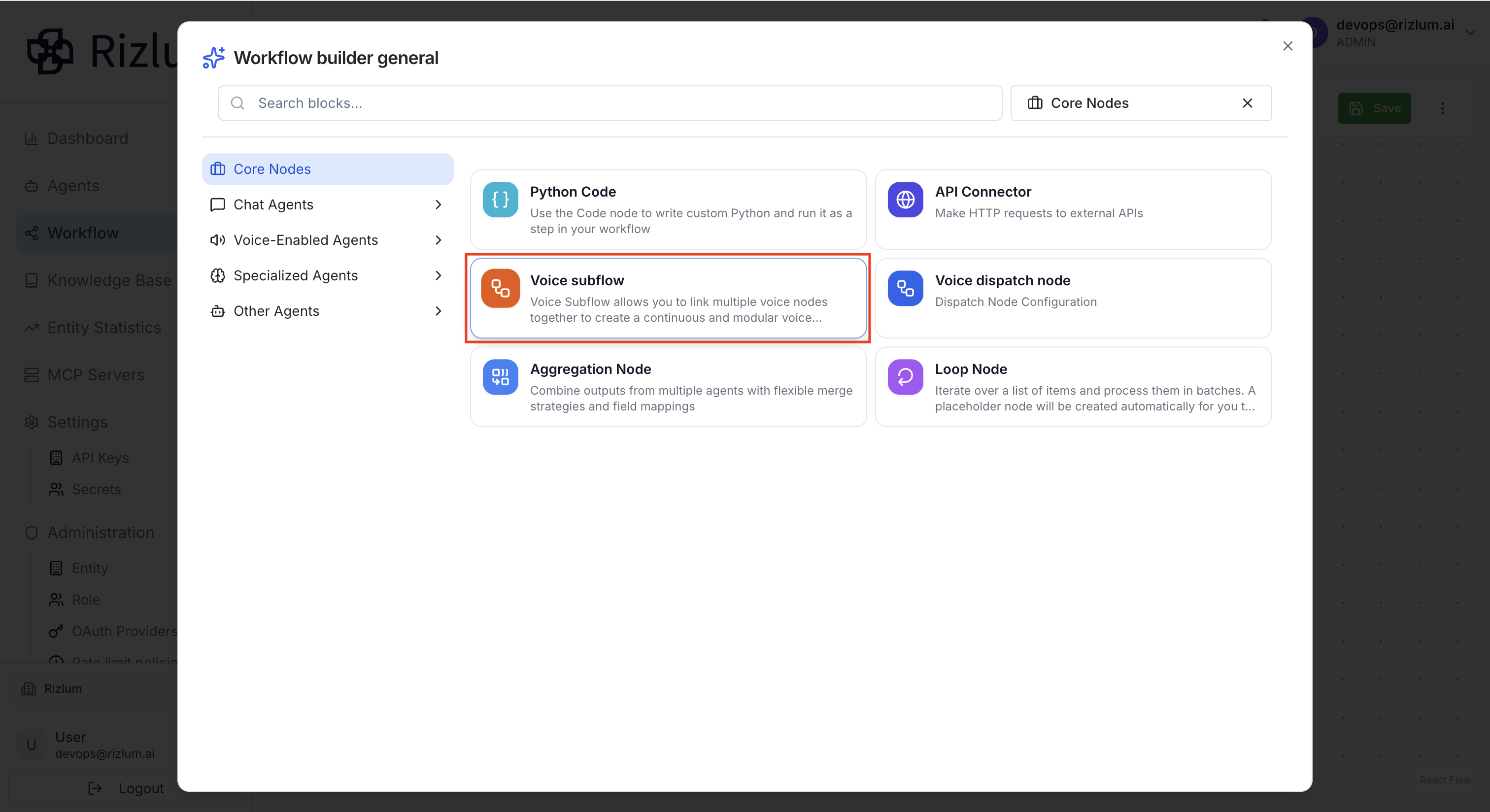 2.Après avoir ajouté ce nœud, vous pouvez y intégrer des agents vocaux qui représenteront les différentes étapes de l’appel. Pour cela, cliquez sur le bouton avec l’icône + (Voices) situé à droite du nœud. Une fenêtre s’ouvre alors, vous permettant de sélectionner un agent vocal.
2.Après avoir ajouté ce nœud, vous pouvez y intégrer des agents vocaux qui représenteront les différentes étapes de l’appel. Pour cela, cliquez sur le bouton avec l’icône + (Voices) situé à droite du nœud. Une fenêtre s’ouvre alors, vous permettant de sélectionner un agent vocal.
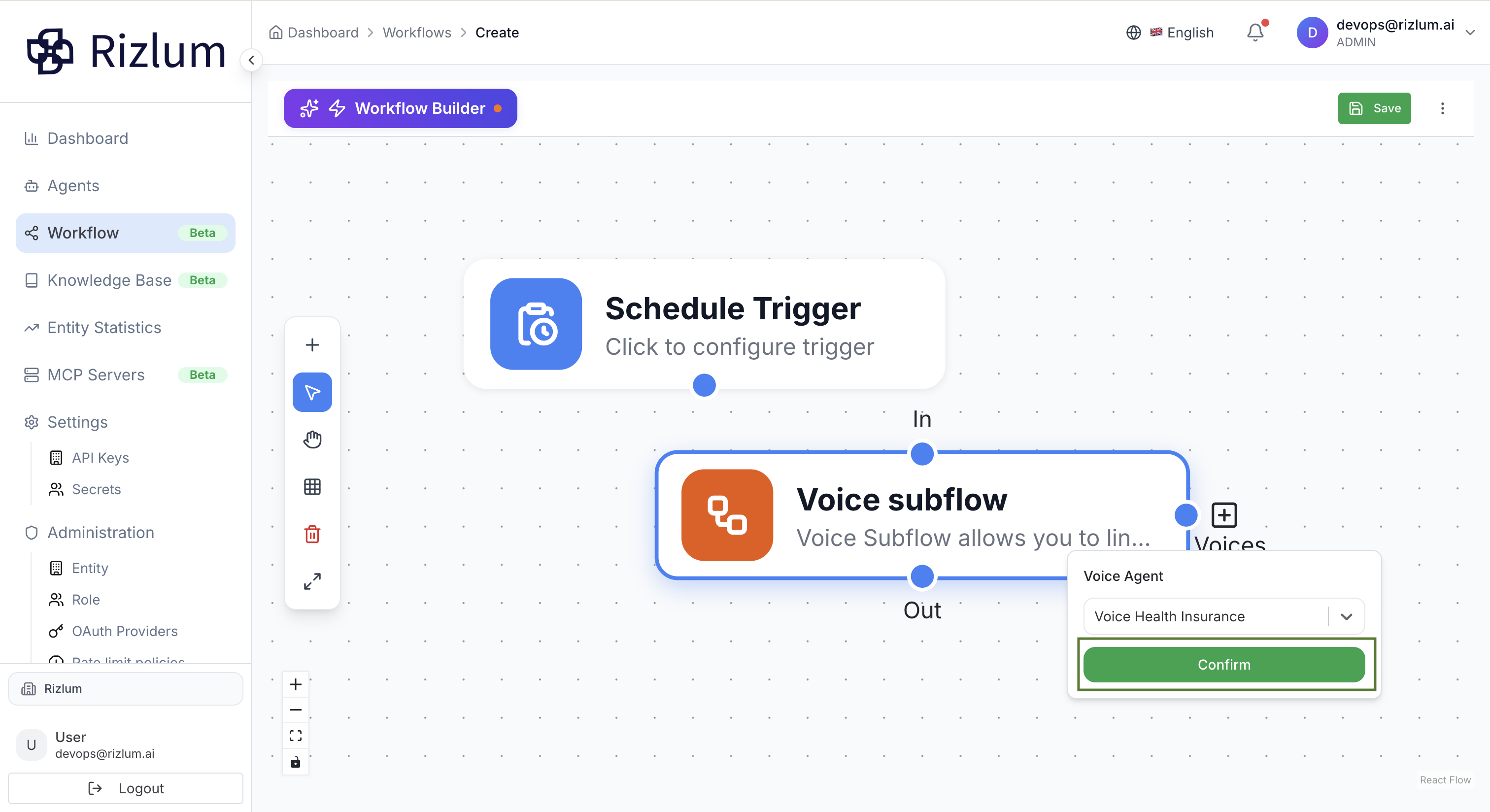
 3.Choisissez l’agent vocal souhaité, puis cliquez sur le bouton Confirmer pour valider votre sélection.
3.Choisissez l’agent vocal souhaité, puis cliquez sur le bouton Confirmer pour valider votre sélection.
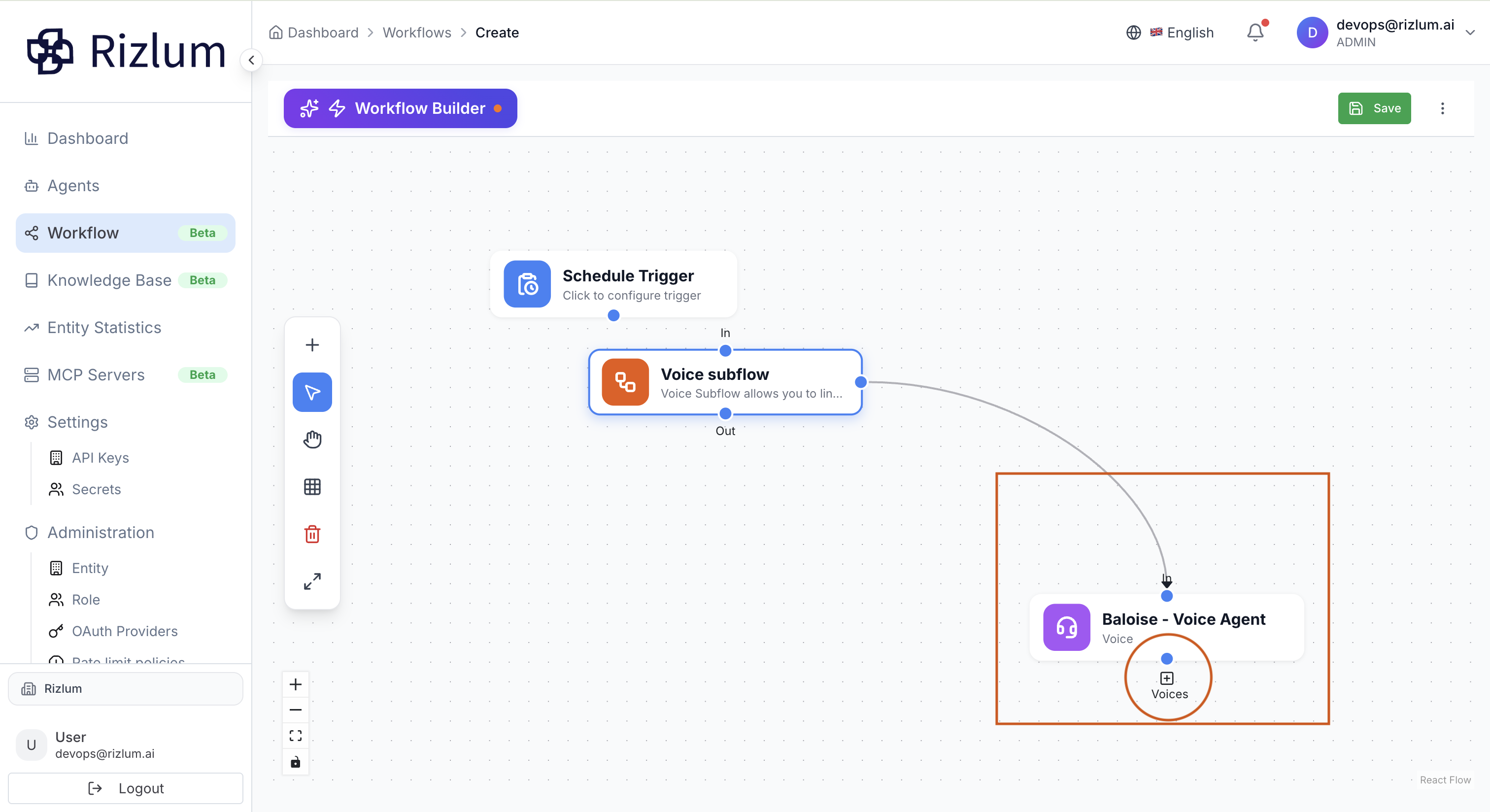
 4.Une fois confirmé, l’agent vocal apparaît dans le workflow et est automatiquement connecté au nœud de sous-flux vocal.
4.Une fois confirmé, l’agent vocal apparaît dans le workflow et est automatiquement connecté au nœud de sous-flux vocal.
 5.Pour ajouter d’autres agents vocaux comme étapes supplémentaires dans l’appel, cliquez à nouveau sur le bouton + (Voices) et répétez la même opération. Vous pouvez ainsi créer une séquence de plusieurs agents vocaux, chacun correspondant à un comportement ou une étape spécifique dans l'appel.
5.Pour ajouter d’autres agents vocaux comme étapes supplémentaires dans l’appel, cliquez à nouveau sur le bouton + (Voices) et répétez la même opération. Vous pouvez ainsi créer une séquence de plusieurs agents vocaux, chacun correspondant à un comportement ou une étape spécifique dans l'appel.
Attention : il est important de bien distinguer les deux zones du workflow. La liste des agents vocaux affichée dans le nœud Sous-flux vocal (zone encadrée en rouge dans l’image) correspond uniquement aux agents ajoutés via le bouton + (Voices). Ces éléments font partie du sous-flux interne et définissent les différentes étapes exécutées pendant l’appel. En revanche, le workflow principal se situe dans la zone violette. La connexion sortante marquée Out depuis le nœud Sous-flux vocal indique la reprise du flux global après l’exécution du sous-flux. Cette séparation permet de différencier clairement la logique interne du sous-flux et le reste du scénario principal.
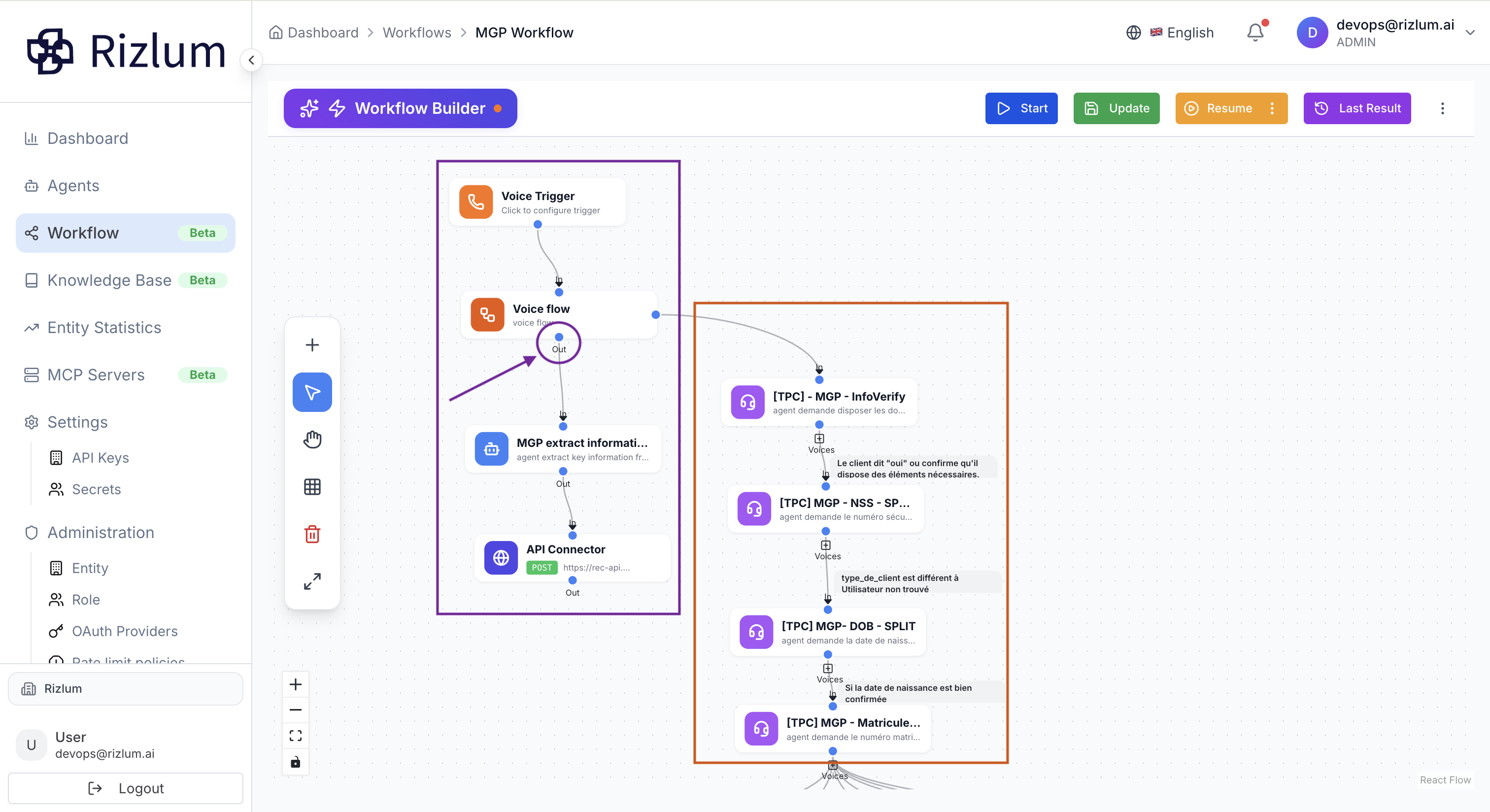
4. Voice Dispatch Node
5. Aggregation Node
Le Aggregation Node permet de fusionner les sorties de plusieurs nœuds en un résultat unique et cohérent, offrant ainsi une vue globale de l’ensemble du workflow sans nécessiter de consolidation manuelle. Cette fonctionnalité est conçue pour centraliser les données issues de différentes étapes de traitement et simplifier leur exploitation.
Il propose plusieurs stratégies de fusion flexibles, telles que merge, array ou nested, permettant d’adapter la structure du résultat final selon les besoins. Des options de résolution des conflits sont également disponibles (first_wins, last_wins ou error) afin de définir précisément le comportement en cas de données contradictoires. L’inclusion des métadonnées peut aussi être activée ou désactivée pour contrôler le niveau de détail des informations agrégées.
Grâce à cette approche, l’Aggregation Node facilite la combinaison de résultats issus de plusieurs analyses ou agents, comme des analyses de sentiment et techniques. Il simplifie les workflows complexes, réduit le temps de traitement et améliore la prise de décision en fournissant une synthèse claire, structurée et exploitable des données.
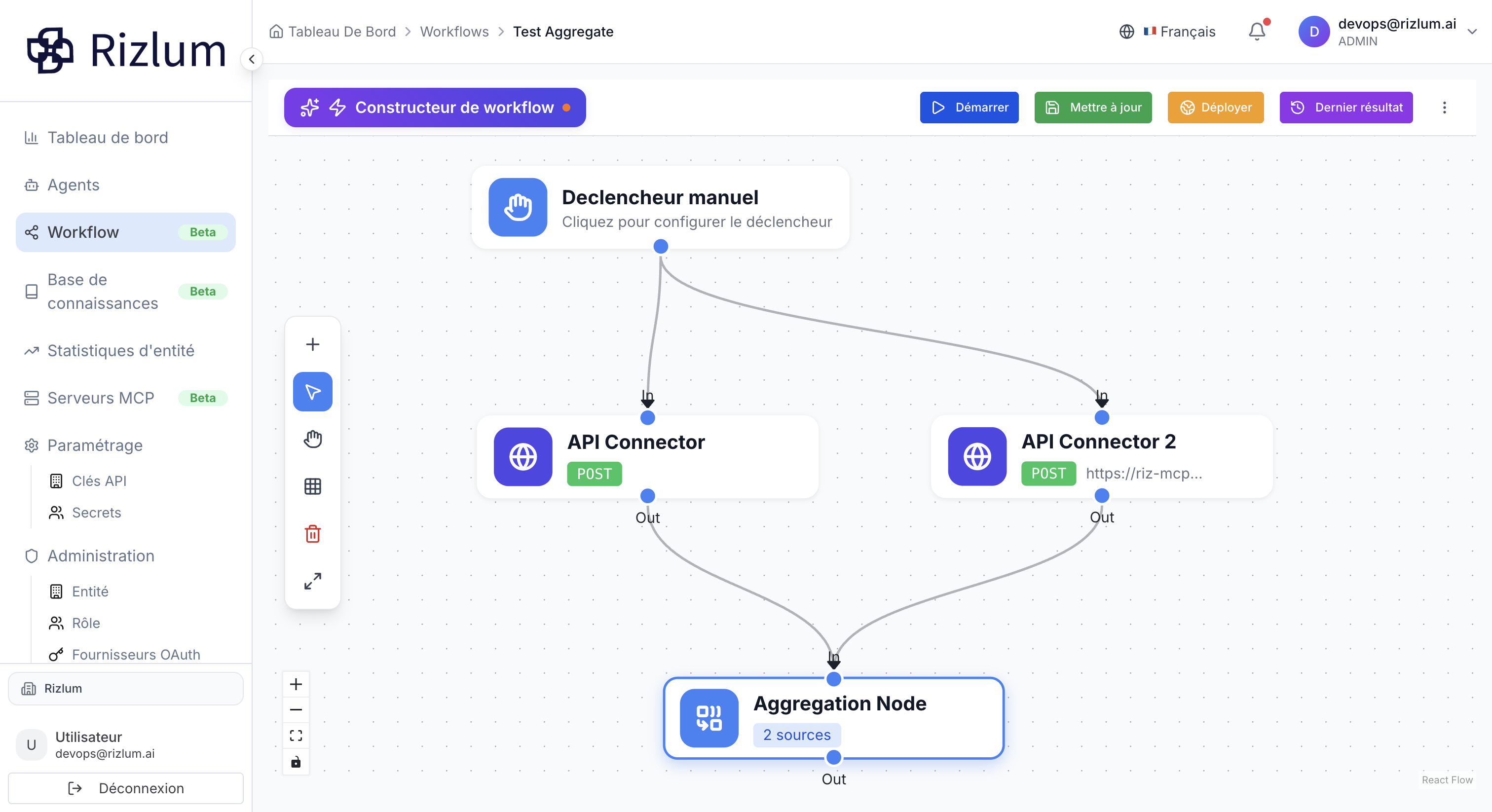
Lorsque l’utilisateur connecte un nœud précédent à un Aggregation Node, la connexion s’affiche automatiquement sur la page de configuration de ce nœud.
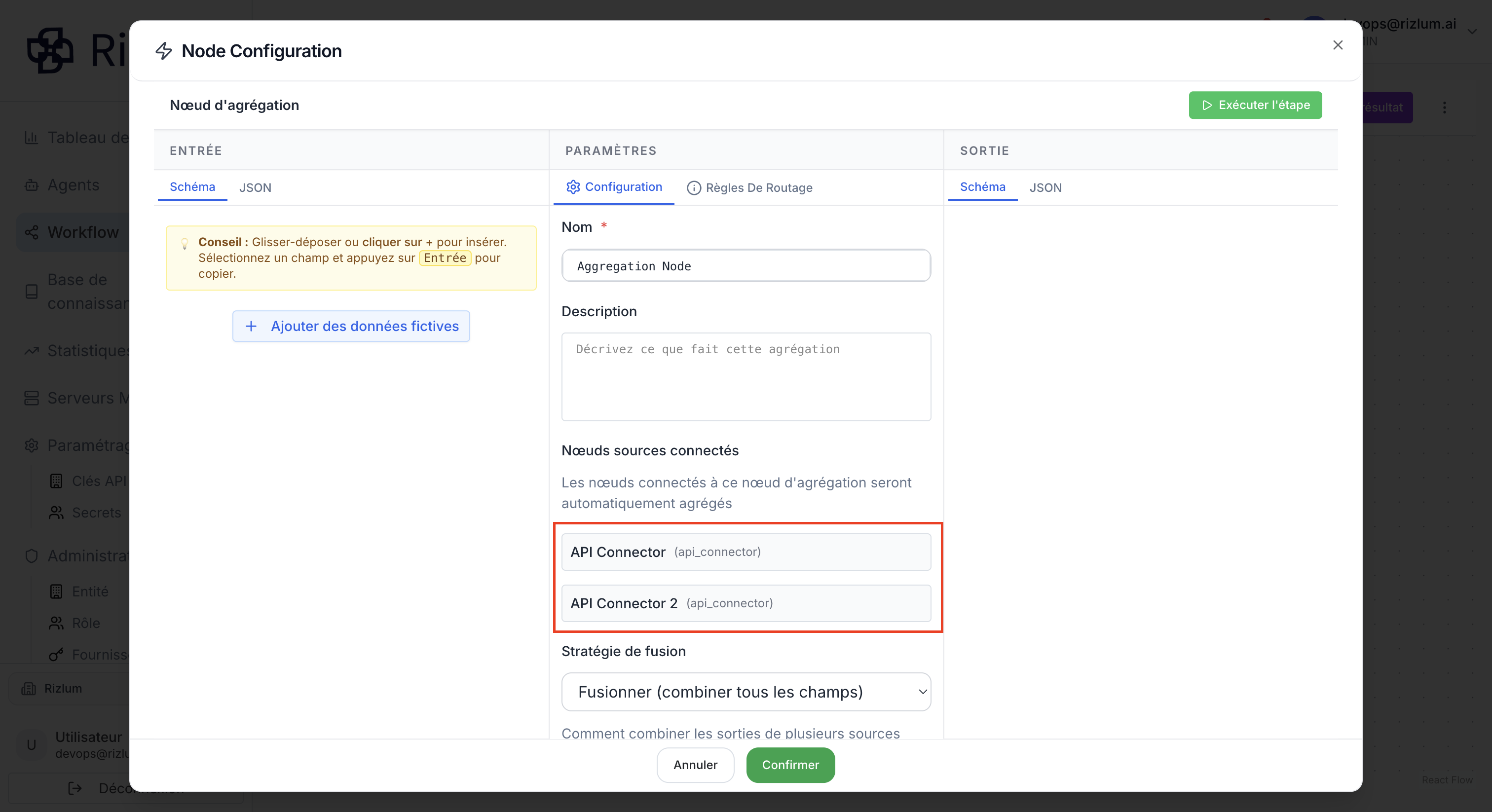
Ces informations ne sont pas modifiables directement dans la page de configuration. Pour les modifier, l’utilisateur doit intervenir sur le plateau de workflow. Ainsi, toute modification (ajout ou suppression de connexions) effectuée directement sur le tableau des nœuds du workflow mettra automatiquement à jour les nœuds précédents connectés à ce nœud dans la page configuration.
Sur la page de configuration de ce nœud, l’utilisateur peut voir des champs pour Stratégie de fusion et Résolution des conflits.
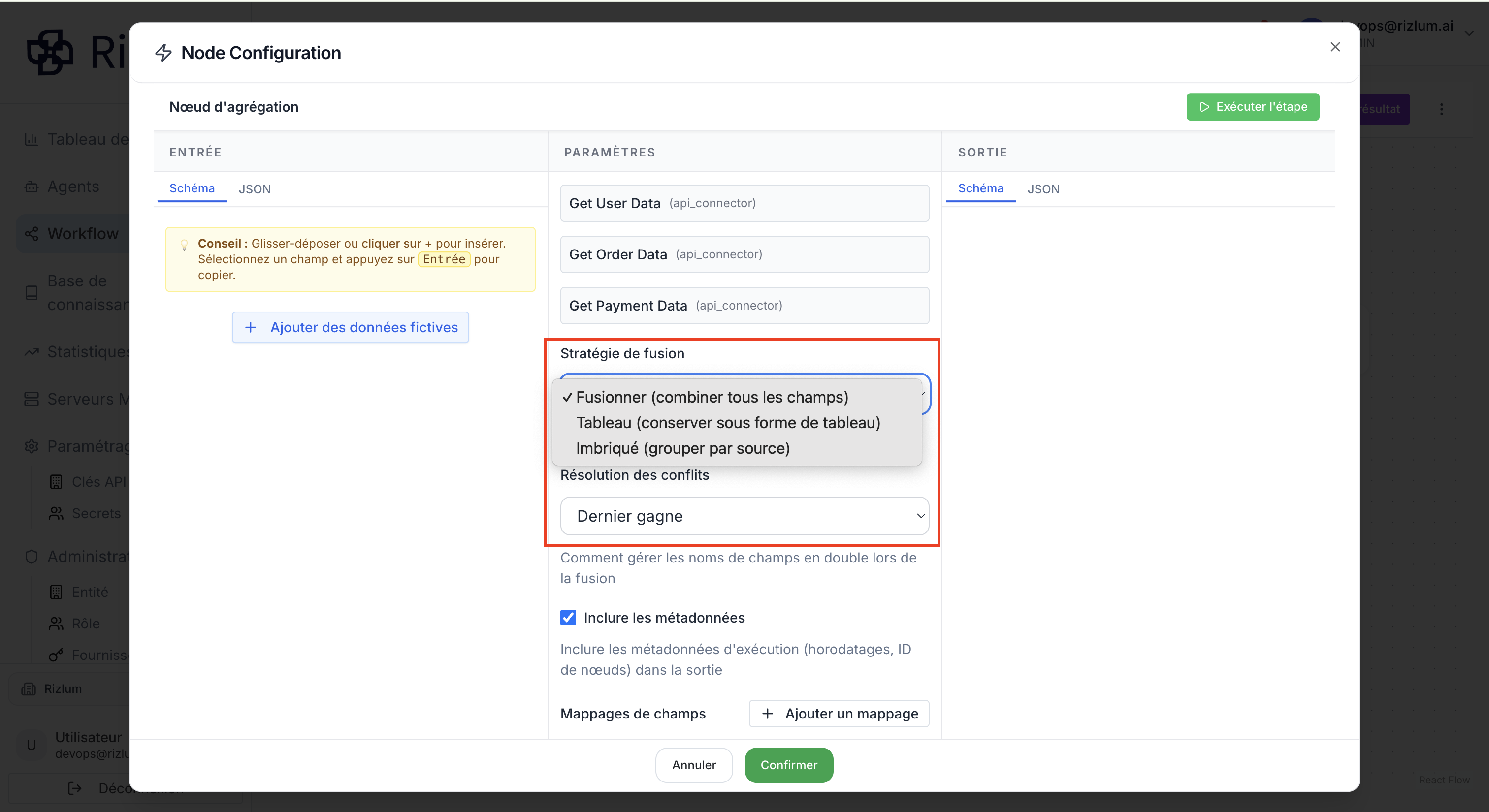
Afin de clarifier dès le départ, ces champs permettent de définir la logique de traitement appliquée par ce nœud aux données en entrée.
Plus précisément, ils déterminent comment le nœud sélectionne, analyse et combine les inputs (provenant des nœuds en amont) afin de produire des outputs conformes aux résultats attendus.
5.1 Stratégie de fusion et Résolution des conflits
Stratégie de fusion : spécifie la méthode de combinaison des différentes sources de données en entrée
Résolution des conflits : définit comment le système gère les cas où des valeurs sont en conflit entre les différentes entrées
Ces paramètres permettent à l’utilisateur de contrôler le comportement du nœud lors du traitement de plusieurs sources de données.
De manière plus détaillée, le champ “Stratégie de fusion” propose trois options :
Fusionner (combiner tous les champs) :
Cette option permet de fusionner l’ensemble des champs provenant des différentes entrées afin de produire un seul jeu de données consolidé en sortie. Dans ce contexte, la gestion des conflits de valeurs devient essentielle, car plusieurs sources peuvent contenir des données différentes pour un même champ.
Ainsi, la résolution des conflits définie dans la configuration du nœud est appliquée lors de la fusion, selon la règle choisie, par exemple :
Dernier gagne (dernière valeur prioritaire) : en cas de conflit (par exemple deux valeurs pour le même champ), la valeur la plus récente écrase les précédentes
Premier gagne (première valeur prioritaire) : en cas de conflit (par exemple deux valeurs pour le même champ), la première valeur rencontrée est conservée
Tableau (conserver tous les champs) : toutes les valeurs en conflit sont conservées sans écrasement, et regroupées sous forme de liste (array) afin de préserver l’ensemble des données
Erreur (lever une erreur en cas de conflit) : si un conflit est détecté pour un même champ, le traitement est interrompu et une erreur est générée
Cette stratégie garantit un comportement déterministe lors de la combinaison des données en entrée.
Array :
Cette stratégie ne réalise pas de fusion au niveau des champs. Les données provenant des différentes entrées sont conservées et regroupées sous forme de tableau (array).
Chaque entrée reste intacte, sans écrasement ni résolution de conflit.
Erreur (lever une erreur en cas de conflit)
Cette stratégie impose une validation stricte des données.
Si un conflit est détecté entre les entrées (valeurs différentes pour un même champ), le traitement est interrompu et une erreur est générée.
5.2 Inclure les métadonnées
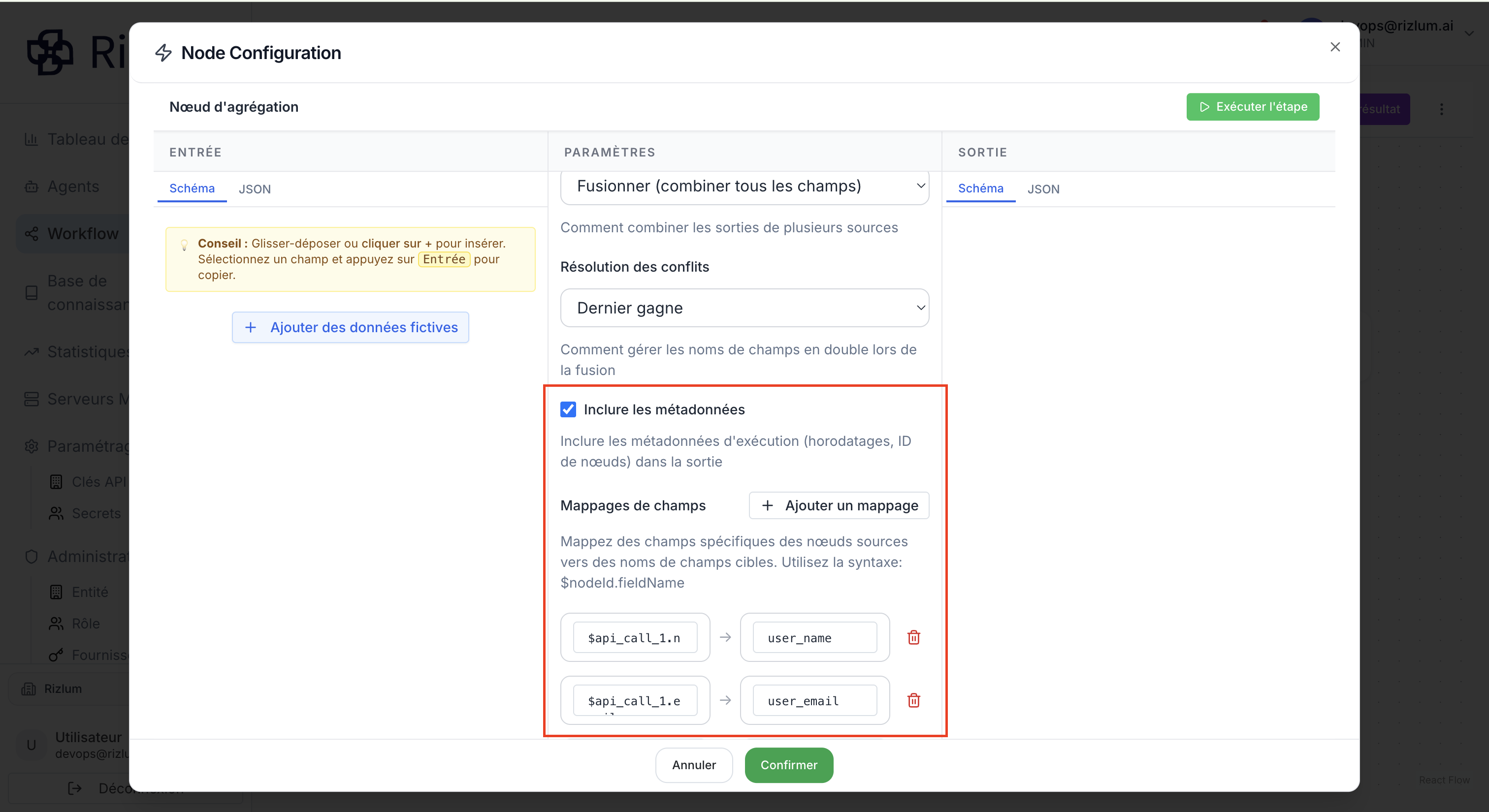
L’option Inclure les métadonnées d’exécution permet d’ajouter des informations supplémentaires à la sortie du nœud. Ces métadonnées ne font pas partie des données métier, mais fournissent un contexte sur l’exécution du workflow. Elles incluent notamment des éléments comme les horodatages, les identifiants des nœuds et d’autres informations techniques utiles pour le débogage et la traçabilité.
Lorsque cette option est activée, la sortie inclut des champs techniques tels que l’heure d’exécution (timestamp), les ID des nœuds ayant traité les données, ainsi que des informations sur le chemin d’exécution. Ces données permettent de comprendre comment et quand chaque résultat a été généré, facilitant ainsi l’analyse des flux et la résolution d’éventuels problèmes.
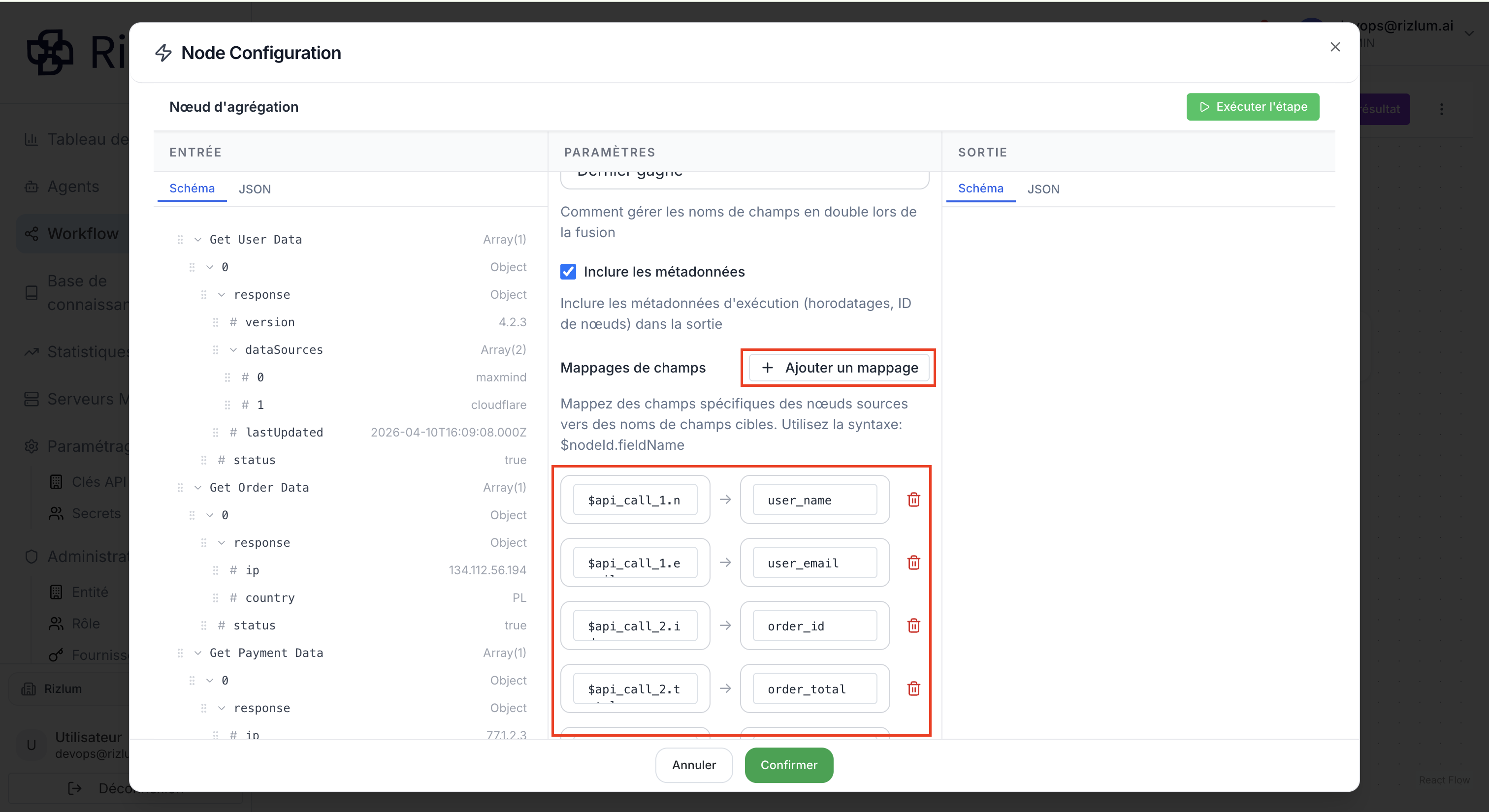
5.3. Mappages de champs
La section Mappages de champs permet de définir explicitement comment les données issues des nœuds sources sont transformées et renommées dans la sortie du nœud. L’utilisateur peut créer un ou plusieurs mappages afin de sélectionner des champs précis provenant des nœuds en amont et de les associer à des noms de champs cibles.
Pour référencer une valeur d’entrée, il faut utiliser la syntaxe $nodeId.fieldName, où nodeId correspond à l’identifiant du nœud source et fieldName au nom du champ à extraire. Cela permet de contrôler précisément la structure du résultat final.
Cette fonctionnalité est utile pour normaliser les données, éviter les ambiguïtés entre sources multiples et construire une sortie structurée et prévisible.
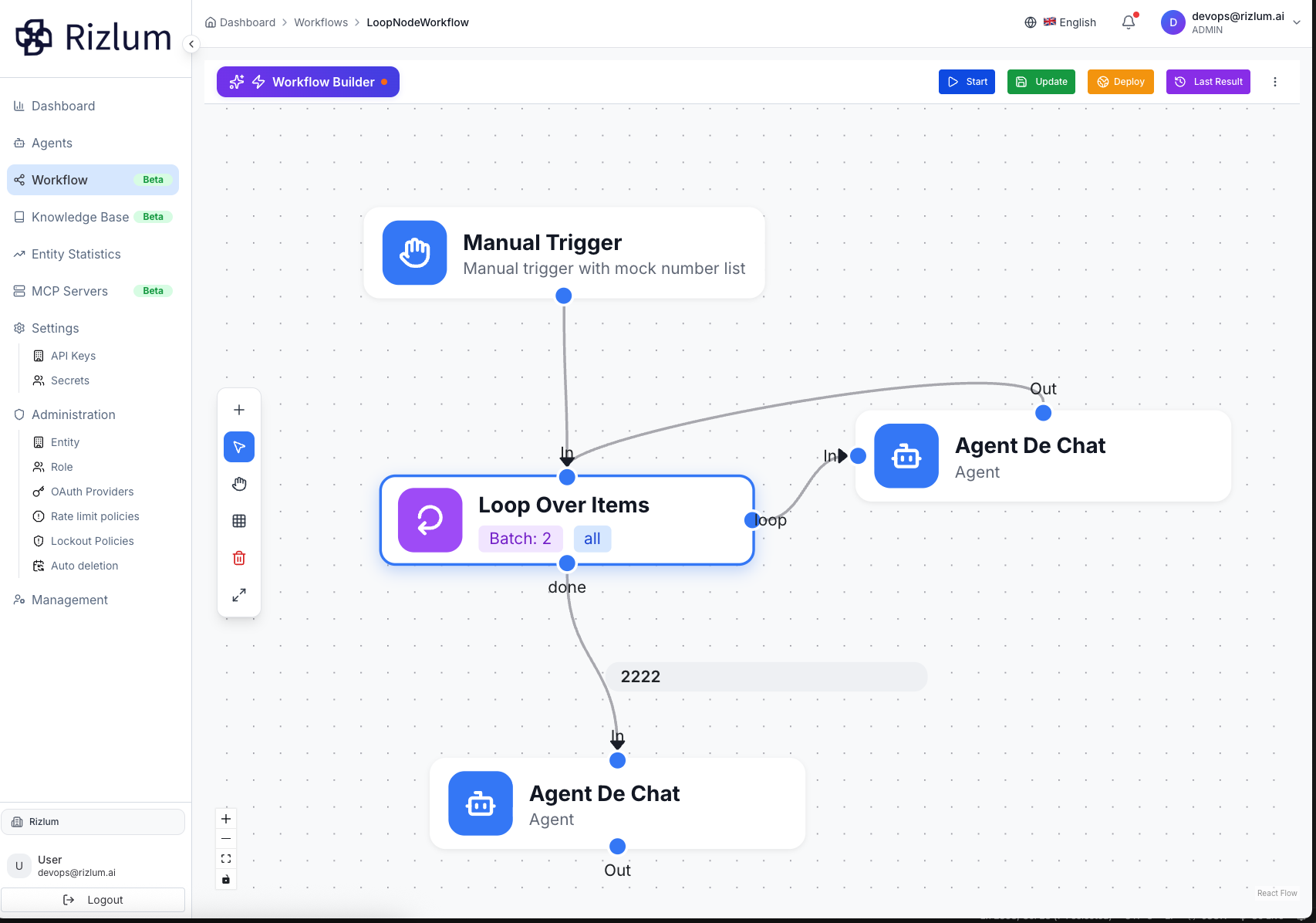
6. Loop node
Le Loop Node est une fonctionnalité qui permet de traiter automatiquement des listes d’éléments par lots (Batch processing). Il offre la possibilité de définir le nombre d’éléments à traiter à chaque itération ainsi que le nombre de cycles à exécuter. Il permet également de configurer le comportement en cas d’erreur, notamment la poursuite ou l’arrêt du traitement. Cette flexibilité rend le processus de traitement plus structuré, contrôlé et adapté aux workflows automatisés.
Il permet également de gérer l’affichage des résultats en choisissant entre la sortie du résultat final uniquement ou la visualisation de tous les résultats générés à chaque cycle. Cette option est utile pour le suivi détaillé ou pour une vue synthétique selon les besoins. Le Loop Node s’intègre avec les agents configurés dans le système, ce qui permet d’automatiser des workflows complexes, de réduire les interventions manuelles et d’assurer une exécution fiable et cohérente des tâches répétitives.